
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- ChatGPT 설명
- Selection Sort
- chatGPT
- 선택정렬
- 이진탐색
- BERT
- Discrete Wavelet Transform
- GPT-3
- 선택정렬 증명
- 이진탐색 증명
- Binary Search Proof
- binary search
- haar matrix
- Proof Selection Sort
- Today
- Total
Just Do IT
문과생이 쉽게 설명하는 ChatGPT,GPT(ChatGPT란?, GPT-3란?) 본문
0. 들어가며
일론머스크가 공동창업자로 있었던 OpenAi에서 22년 11월 30일날 베타테스트를 시작한 ChatGPT가 연일 이슈입니다.
GPT-3가 나왔을 때는 AI를 공부하던 사람들과 업계에서 큰 이슈가 되었다면 이번 ChatGPT는 일반 대중들에게 까지도 소개가 될 만큼 대단한 영향력을 끼치고 있습니다.
그래서 이번 기회에 GPT의 역사를 쉽게 설명해서 정리해보려고 합니다.

1. GPT란?
ChatGPT라는 이름을 두 단어로 쪼개보면 Chat과 GPT로 쪼갤 수 있습니다.
말그대로 채팅에 특화되어있는 GPT모델 이라는 뜻입니다. GPT모델은 OpenAI가 개발한 Pre-Trained 모델로 transformer의 decoder만 사용한 구조로 되어있습니다.
GPT는 Generative Pre-trained Transformer의 앞글자를 딴 단어입니다.
현재 GPT-3까지 개발되어 있으며 곧 GPT-4가 나온다는 소식이 있습니다.
그리고 GPT-4가 나오기 전 GPT-3.5정도로 ChatGPT가 나온것입니다.
GPT-3가 나왔을 때도 놀라운 성능을 보여줬는데 GPT-4는 그것보다 훨씬 뛰어난 성능을 낸다고 합니다.
GPT는 분류,대화,번역,요약,Q&A등 많은 task에 사용될 수 있고 문장 생성에 장점이 있습니다.
예를 들면 특정 키워드를 주고 시나 가사를 생성해주거나 뉴스나 글을 글 내부에서는 사용하지 않았던 단어나 문장을 이용하여 매끄럽게 요약해 줄 수 있습니다.
그 중에서 챗봇과 같이 사용자의 질문에 대한 답변을 위해서는 질문을 이해하고 답변을 '생성'해야 하기 때문에 ChatGPT가 혁신적인 성능을 낼 수 있었던 것입니다.
OpenAI가 만든 GPT-3말고 우리나라에도 카카오가 만든 KoGPT가 있습니다. KoGPT는 한국어에 특화된 GPT모델로 대중에게 공개되어있습니다.
https://github.com/kakaobrain/kogpt
GitHub - kakaobrain/kogpt: KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
KakaoBrain KoGPT (Korean Generative Pre-trained Transformer) - GitHub - kakaobrain/kogpt: KakaoBrain KoGPT (Korean Generative Pre-trained Transformer)
github.com
물론 OpenAI가 AI를 모르는 사람들도 쉽게 체험할 수 있게 playground를 따로 만들어 놓은것과는 달리 그냥 Pre-Trained된 모델을 올려놨기 때문에 따로 코딩을 해서 다양한 목적에 맞게 Fine-Tuning해서 사용해야 합니다.
- 물론 GPT계열은 Fine-Tuning하지 않고도 Few-Shot learning을 통해 사용 목적에 맞게 출력을 만들 수 있지만 흔히 사용되는 fine-tuning에 대해서만 설명하겠습니다.
글을 쓰면서 볼드체로 진하게 사용해놓은 부분은 AI를 공부하지 않은 분들은 잘 모르는 부분일 것 같습니다. 그렇기 때문에 뒤에서 저 단어들이 뭔지 하나하나 설명하겠습니다.
2. Pre-trained 모델이란?
GPT는 pre-trained 모델이라고 했습니다. 한국말로 하면 사전학습된 모델 이라는 뜻입니다.
사전학습 모델은 특정 task(문제)를 해결하는 방법을 학습한 모델입니다.
이렇게 사전학습된 모델을 이용해서 내가 원하는 task에 맞게(사전학습된 task와 비슷한 task) 추가적으로 학습을 시키면 모델이 내 목적에 맞게 학습됩니다.
여기서 내가 원하는 task에 맞게 추가적으로 학습시키는 것을 'Fine-Tuning한다' 라고 합니다.
그리고 pre-trained된 모델을 여러 task에 이용하는 것을 전이학습(Transfer-learning)이라고 합니다.
수영으로 비유하자면 자유형만 연습해서 잘하는 사람이라고 생각하면 쉽습니다.
만약 내가 원하는 task가 평형을 하는것 이라면 아예 처음부터 평형을 도전하는 사람은 물에 들어가서 숨쉬는법, 뜨는법 등등을 모두 새로 학습해야 하지만 자유형을 이미 학습한 사람(pre-trained model)은 자유형을 하는 방법에서 조금만 수정하면(Fine-tuning) 쉽게 평형을 할 수 있는 것 처럼 말입니다.
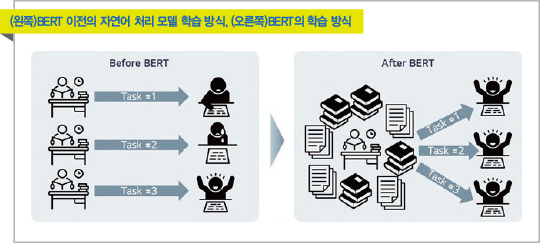
설명을 듣고 그림을 보면 이해가 쉬울것이라고 생각합니다.
그림은 BERT를 설명하고 있지만 BERT또한 GPT와 같은 transformer 계열의(BERT는 transformer의 인코더, GPT는 디코더를 사용했다는것이 차이점) Pre-trained model이기 때문에 그림을 가져왔습니다.
원래는 왼쪽과 같이 하나의 모델은 하나의 task를 처리하기 위해 학습됐지만 transfer learning의 개념이 등장한 이후로 하나의 pre-training 모델을 여러 task에 적용할 수 있게 된 것입니다.
BERT와 GPT를 흔히 초 거대 ai모델이라고 합니다.
학습을 위해서는 수많은 데이터와 학습 시간이 필요하고 이를 뒷받침 해줄 고성능 컴퓨팅 자원이 필요합니다.
따라서 사전 학습된 초 거대 ai 모델을 내 목적에 맞게 미세 조정 하면 되기 때문에 pre-trained 모델이 유용하게 사용되고 있습니다.
3. Transformer란?

Transformer란 구글이 2017년에 개발한 AI 모델 구조입니다.
Transformer가 있었기에 GPT가 나올 수 있었습니다. 구글이 발표한 transformer의 구조를 이용해 OpenAI가 GPT를 만들고 구글의 경쟁자인 마이크로소프트가 이에 투자해서 마소의 빙에 chatgpt를 추가해 구글을 견제하고 있다는 사실이 참 재밌는 것 같습니다. 구글도 chatgpt에 위기를 느끼고 bard라는 챗봇을 발표했습니다.
본론으로 들어가 Transformer를 설명하려면 Attention을 알아야합니다. 트랜스포머는 어텐션만을 이용해 구현한 모델이기 때문입니다. 그렇기 때문에 Transformer의 논문 제목도 'Attention is all you need' 입니다.

그리고 안타깝게도 Attention을 설명하려면 RNN을 이용한 Seq2Seq 구조도 알아야합니다. AI를 공부하지 않으신분들을 위한 글이기 때문에 하나하나 간단하게 설명해보도록 하겠습니다.
3-1. RNN을 이용한 Seq2Seq
RNN은 순환신경망으로 순서를 가지고 입력되는 음악, 텍스트, 동영상 등을 처리하기 위해 만들어진 인공신경망입니다. RNN을 자세히 설명하면 글이 지금보다 훨씬 길어지기 때문에 추후에 포스팅을 하던가 하겠습니다.
혹시 궁금하시다면 밑의 글을 참고하시면 좋을 것 같습니다.
https://dreamgonfly.github.io/blog/understanding-rnn/
Recurrent Neural Network (RNN) 이해하기 | Dreamgonfly's blog
Recurrent Neural Network (RNN) 이해하기# 음악, 동영상, 에세이, 시, 소스 코드, 주가 차트. 이것들의 공통점은 무엇일까요? 바로 시퀀스라는 점입니다. 음악은 음계들의 시퀀스, 동영상은 이미지의 시퀀
dreamgonfly.github.io
RNN보다 발전된 LSTM, GRU(자랑스러운 한국인 조경현 교수님이 참여)등이 실제로는 쓰이지만 그냥 RNN으로 부르도록 하겠습니다. 텍스트 또한 순서에 따라 의미가 변하기 때문에 RNN을 이용하여 task를 처리했습니다. 번역을 예로 들면 'i love you'는 '난 너를 사랑해'로 번역되어야 하고 'you love me'는 '넌 나를 사랑해'로 번역되어야 하는 것 입니다. 이런 번역을 위해 자주 쓰이던 구조가 Seq2Seq이라고 불리는 sequence to sequence 구조 입니다.
간단히 seq2seq구조를 설명하면 위의 움짤과 같이 RNN들로 이루어진 encoder에 번역하고 싶은 단어를 집어넣으면 RNN들로 이루어진 decoder에서 번역된 단어가 하나씩 출력되는 구조입니다.
'I love you'를 입력으로 넣으면 encoder RNN이 이 입력을 처리해서 'i love you'라는 뜻을 품고있는 하나의 벡터를 내놓고 decoder RNN은 이 벡터를 이용해서 번역된 '난 널 사랑해'를 내놓게 되는 것입니다.
3-2. Seq2Seq의 문제와 Attention의 등장
그렇다면 위의 구조는 무엇이 문제일까요? 바로 디코더가 'I love you'를 한국어로 해석하려고 할 때 인코더 RNN이 내놓은 하나의 벡터만을 이용한다는 점입니다.
'I love you'가 아니라 하나의 뉴스나 지문 등을 해석하려고 할 때 그 모든 의미를 하나의 벡터로 표현해 놓으면 디코더의 품질은 떨어질 것입니다. 예를들어 애국가 1절을 영어로 번역한다고 하면 번역된 첫 단어는 뭐가 나와야 할까요? 단순 Seq2Seq구조로는 해결하기 힘들 것 같습니다.
이 때 등장한게 바로 Attention입니다. Attention이 나온 이후로 파파고와 같은 번역의 품질이 혁신적으로 좋아졌습니다.
그리고 이 Attention 매커니즘을 개발한 분 중 한명이 아까도 등장했던 조경현 교수님 입니다.(정말 자랑스러워 해도 좋은 업적입니다 이 Attention이 transformer의 시작이기 때문이죠)
Attention은 Seq2Seq구조에서 decoder가 처리될 때 단순히 encoder에서 나온 벡터 하나만을 보는것 이 아니라 어떤 encoder의 입력을 집중해서 봐야할 지를 결정해 줍니다.
예를들어 애국가 1절을 사람이 영어로 번역한다고 하면 가장먼저 어디를 번역할까요? 당연히 '동해물과'를 보고 번역하겠죠. 이와 비슷하게 attention을 통해 decoder의 첫 출력이 encoder에서 나온 벡터와 입력의 첫부분인 '동해물과' 둘을 모두 보고 번역을 실시할 수 있게 됩니다. 내가 지금 어디에 집중(attention)해야 하는지 알려줄 수 있다는 것입니다.
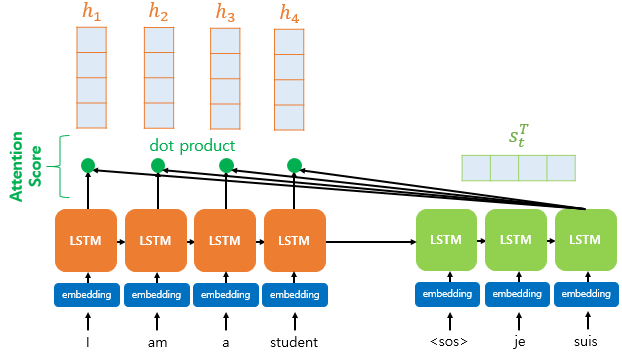
밑의 그림은 attention mechanism을 설명한 그림입니다. 정말정말 간단하게 설명했기 때문에 자세한 내용이 알고싶으신 분들은 구글에 attention mechanism이나 어텐션 메커니즘을 검색하시면 쉽게 설명된 글을 보실 수 있을 것입니다.
3-3. 앞선 빌드업의 종착지, Transformer
이제 attention까지 알게 되었으면 Transformer를 알 수 있습니다.
Seq2Seq구조는 현재의 출력이 어디를 집중해야할지 모르기 때문에 attention 메커니즘을 이용해 집중해야하는 포인트를 알려줌으로써 성능을 끌어 올렸습니다.
하지만 이걸로 충분할까요? Seq2Seq 기반의 어텐션은 encoder와 decoder사이의 attention만을 계산합니다. 하지만 실제로는 encoder사이에서도 연결관계가 존재하고 decoder도 마찬가지 입니다.
추가적으로 RNN은 지금 필요없다고 판단되어서 버려진 특징은 미래의 상황에 절대 쓰일 수 없다는 문제와 병렬처리가 불가능 하다는 문제등을 가지고 있습니다.
이 문제를 해결하기 위해 Seq2Seq 구조의 RNN들을 모두 attention으로 갈아 끼운것이 바로 Transformer입니다. encoder 내에서의 self-attention과 decoder 내에서의 attention,그리고 encoder와 decoder끼리의 attention으로 모두 어텐션을 이용했습니다.
그렇기 때문에 Transformer 논문의 제목이 'Attention is all you need'입니다.
트랜스포머를 통해 계산을 병렬화 하여 학습이 Seq2Seq 보다 훨씬 적은 시간이 소요되며 번역의 성능이 굉장히 좋아졌습니다. 트랜스포머를 모두 설명하려면 이또한 글이 굉장히 길어지기 때문에 논문을 읽고 리뷰하는 형식으로 따로 포스팅해보도록 하겠습니다.
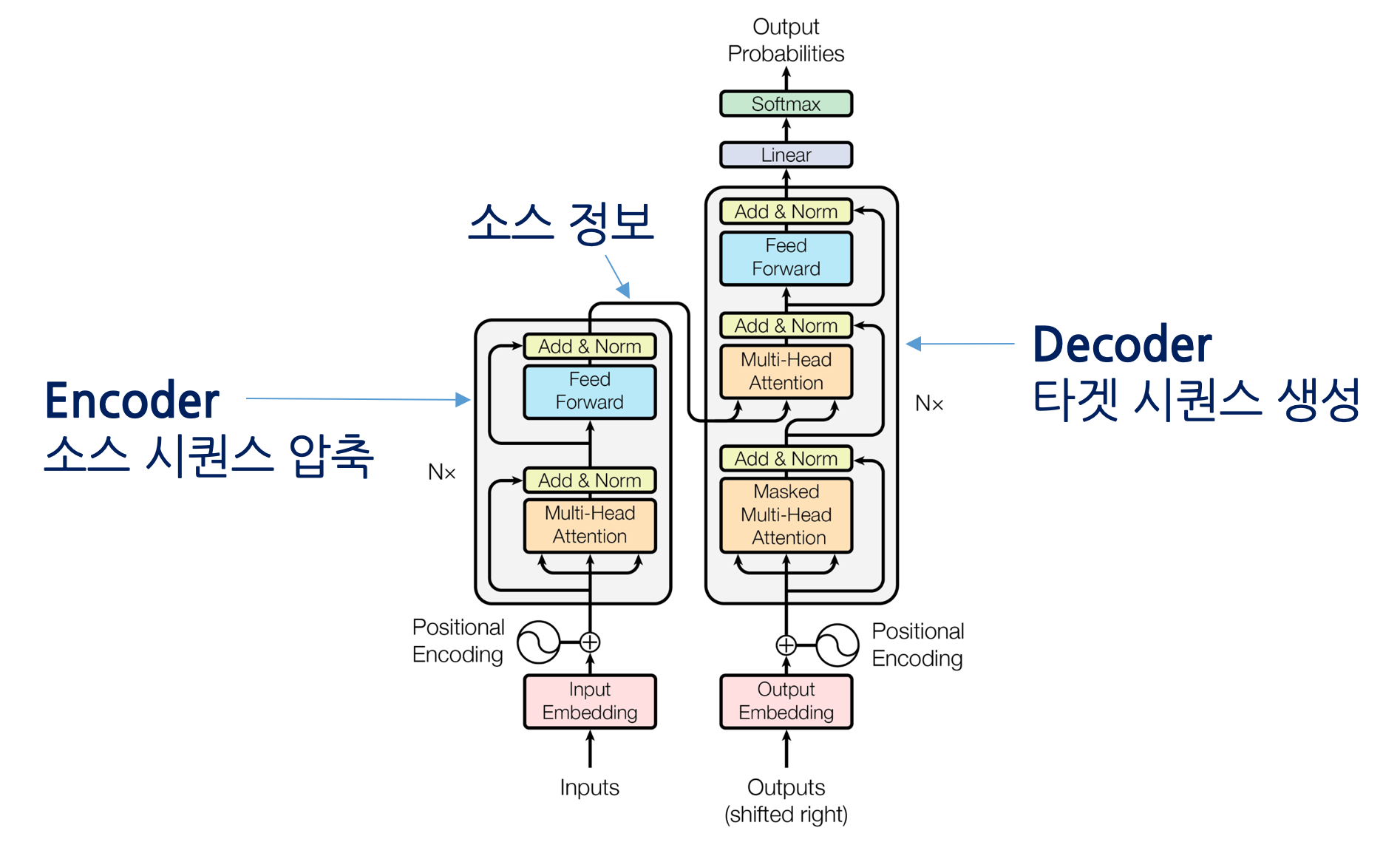
근데 GPT를 아는데 왜 트랜스포머를 알아야 할까요? 바로 GPT는 트랜스포머의 구조에서 디코더 부분을 떼어내 만들었기 때문입니다.
4. GPT와 BERT
GPT는 위에서도 말했다싶이 transformer의 decoder구조로 이루어져있습니다.
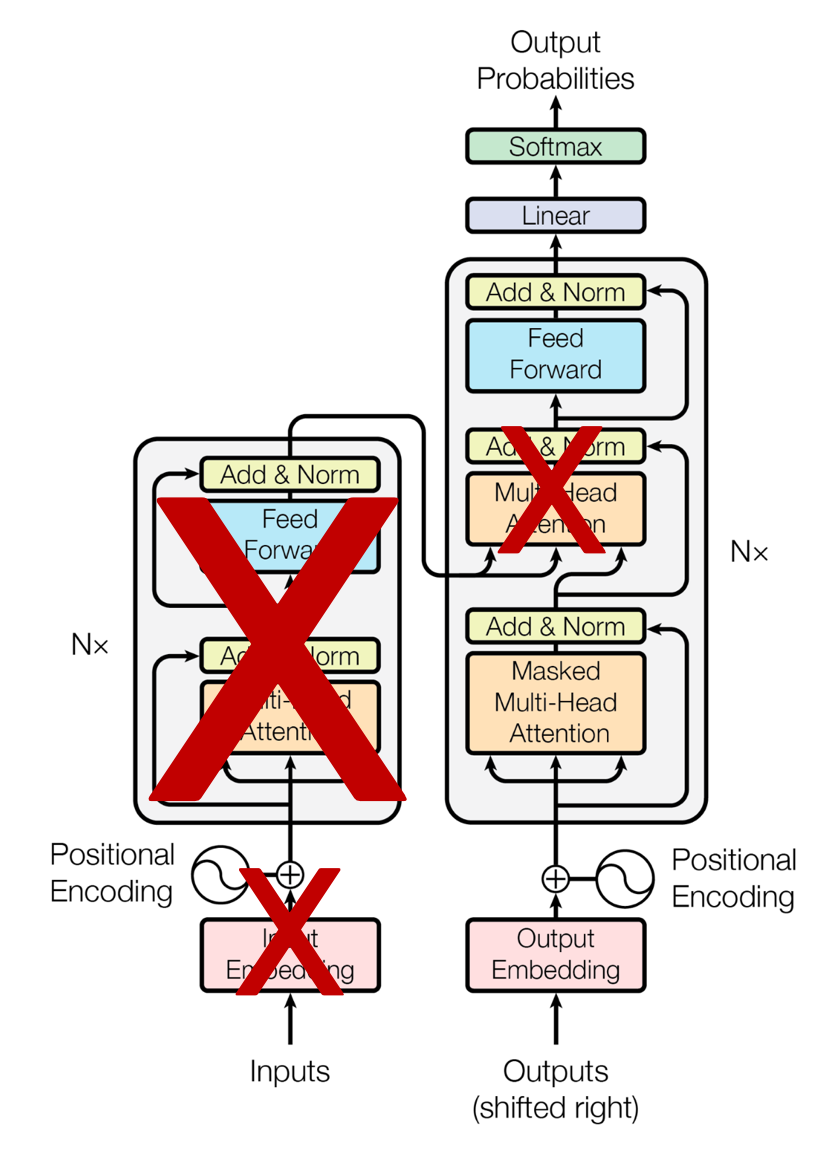
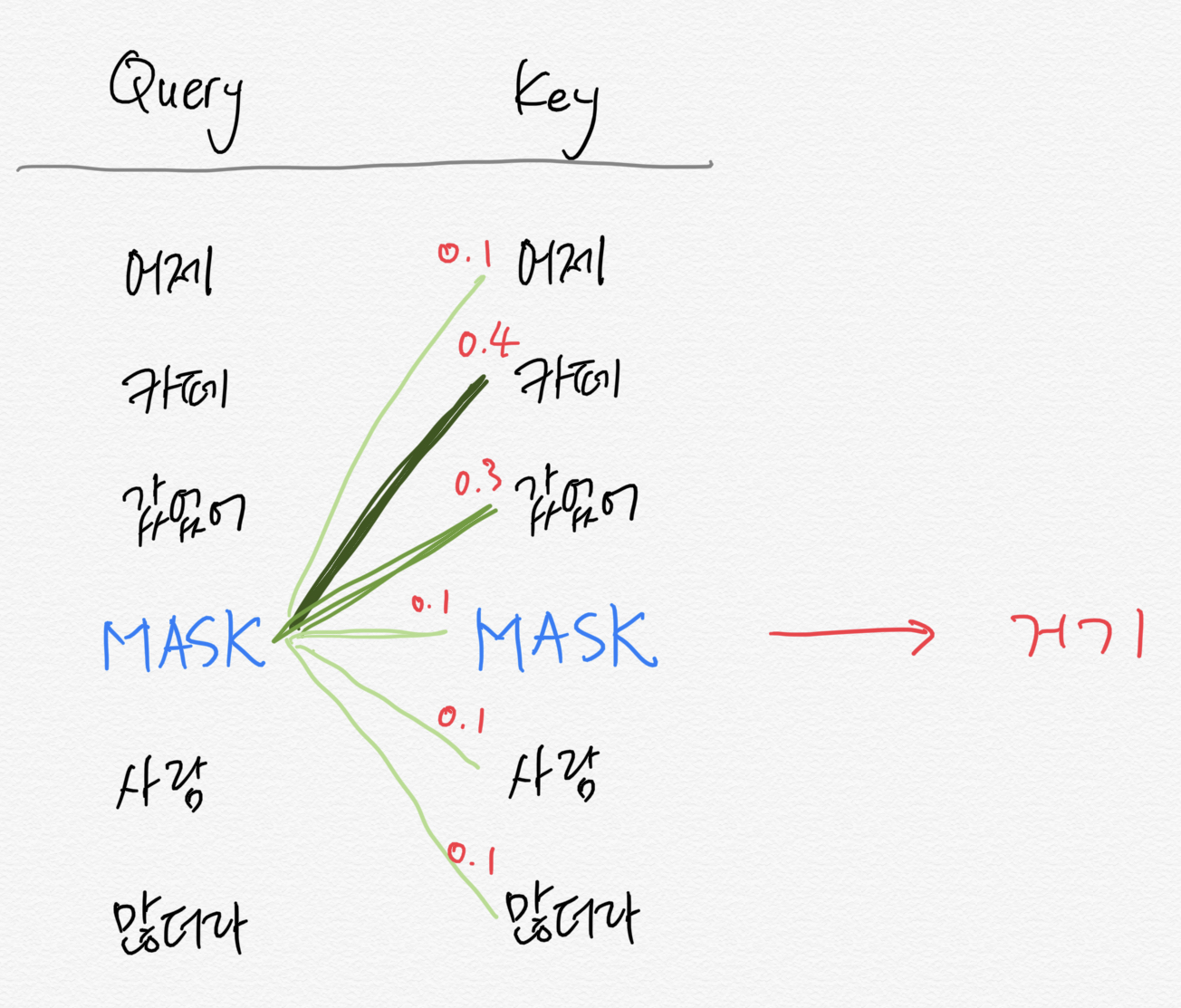
조금은 딥한 이야기를 해보자면 위 그림을 보면 encoder에는 multi-head attention이 사용되지만 decoder에서는 masked multi-head attention이 사용됩니다.
multi-head는 상당히 기술적인 내용이기 때문에 넘어가면 decoder는 masked된다고 했습니다.
mask된다는 것은 가려진다는 것입니다. 따라서 만약 '어제 카페 갔었어 거기 사람 많더라' 라는 문장이 입력이 들어온 경우 처음에는 '어제'를 제외한 나머지 문장을 볼 수 없도록 처리하고 모델은 '카페'라는 단어를 예측해서 생성해야 합니다.
그리고 다음에는 '어제 카페'라는 문장을 제외한 문장이 mask되고 모델은 '갔었어'를 맞춰야 하는 것입니다.
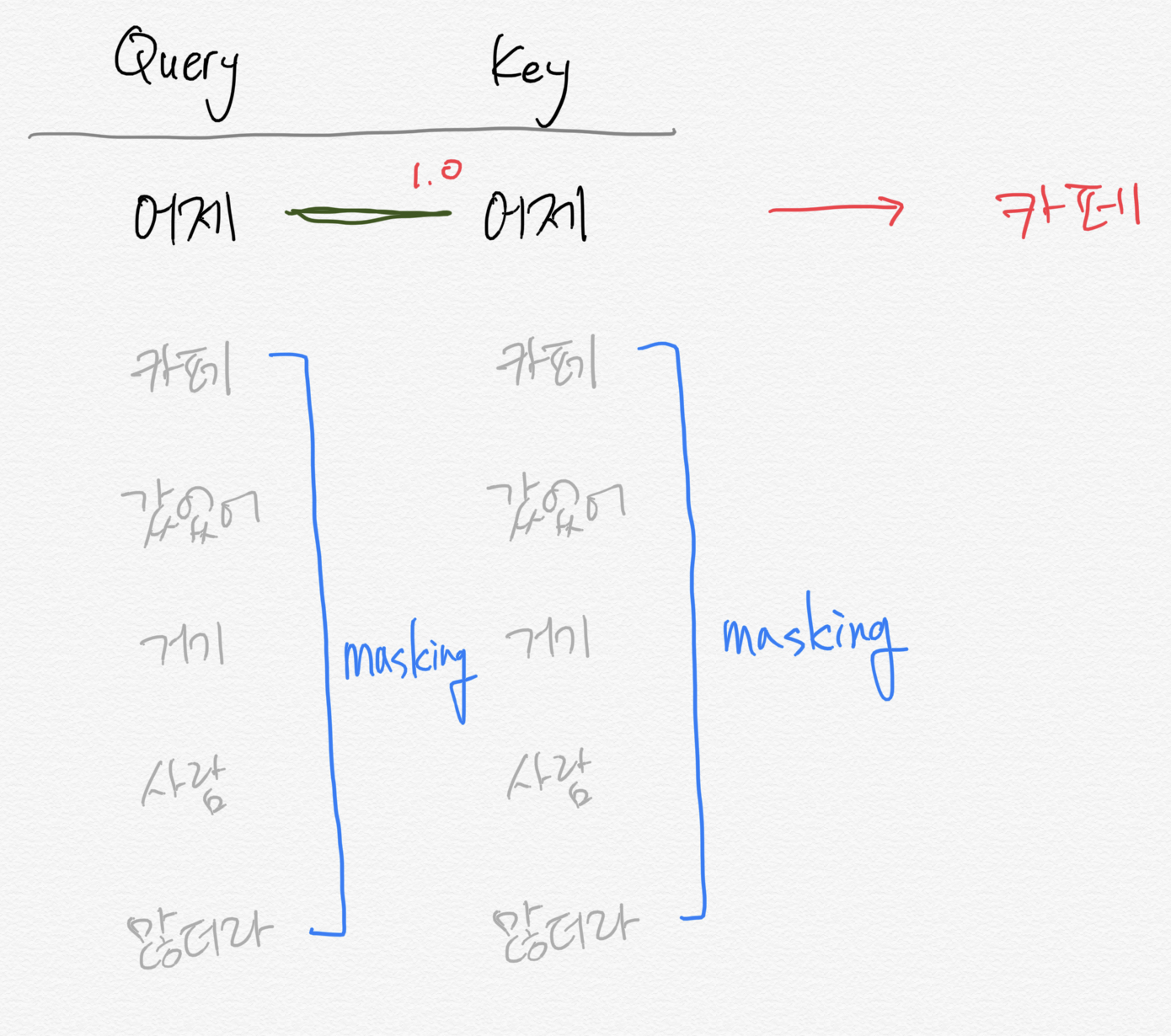
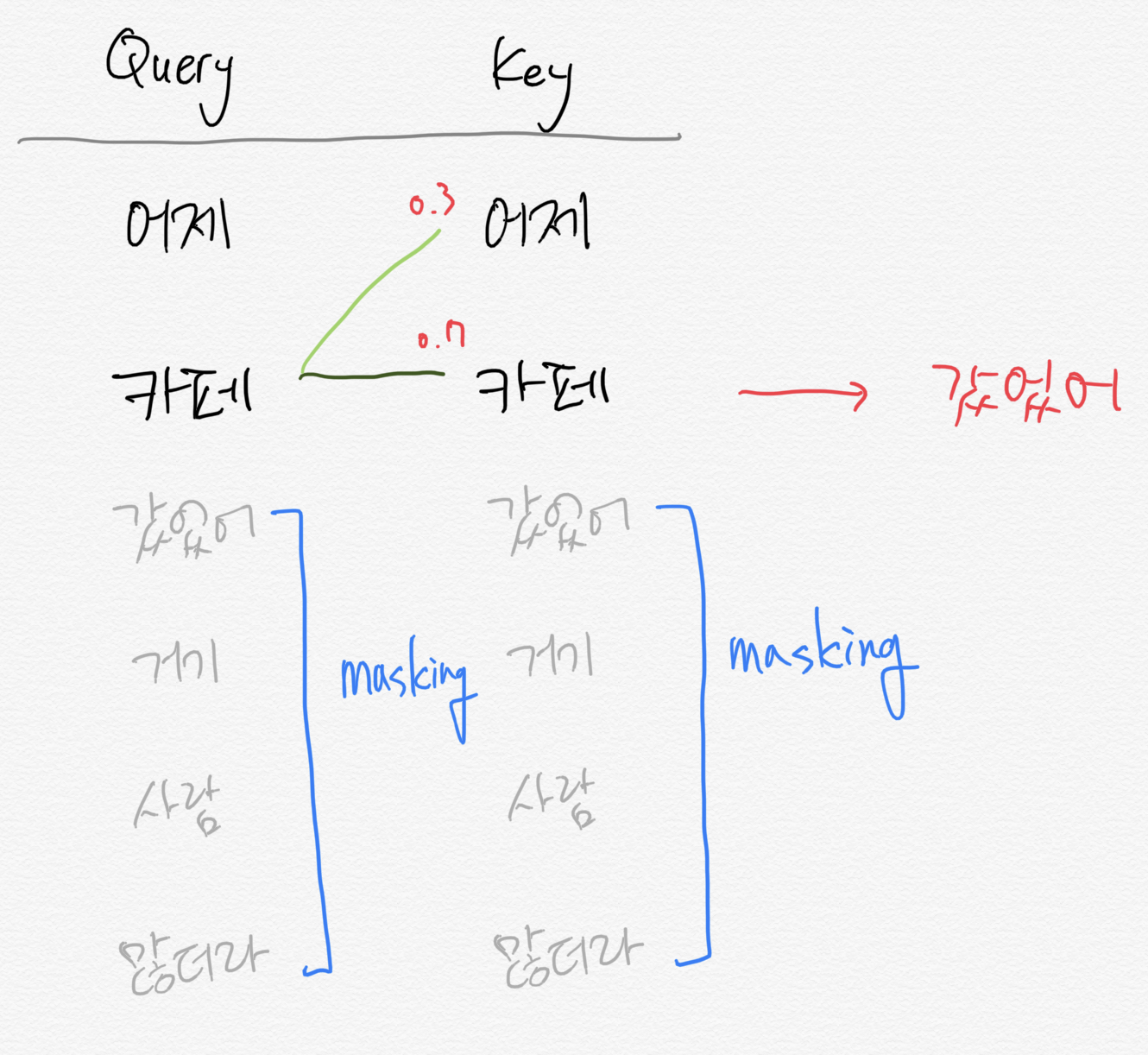
위와 같은 이유로 GPT는 문장을 '생성'하는 task에 강점을 보이게 됩니다.
그렇다면 encoder만을 이용해서 만든 모델도 있겠죠? 이 모델을 BERT라고 합니다.

실제로 약간의 조크를 섞어 위의 Bert를 겨냥하고 BERT를 만들었다고 합니다. 외국 공대생식 유머
아무튼 Bert는 masking하지 않고 입력의 모두를 참조할 수 있기 때문에 문장의 의미 추출에 강점을 지닌다고 알려져있습니다.
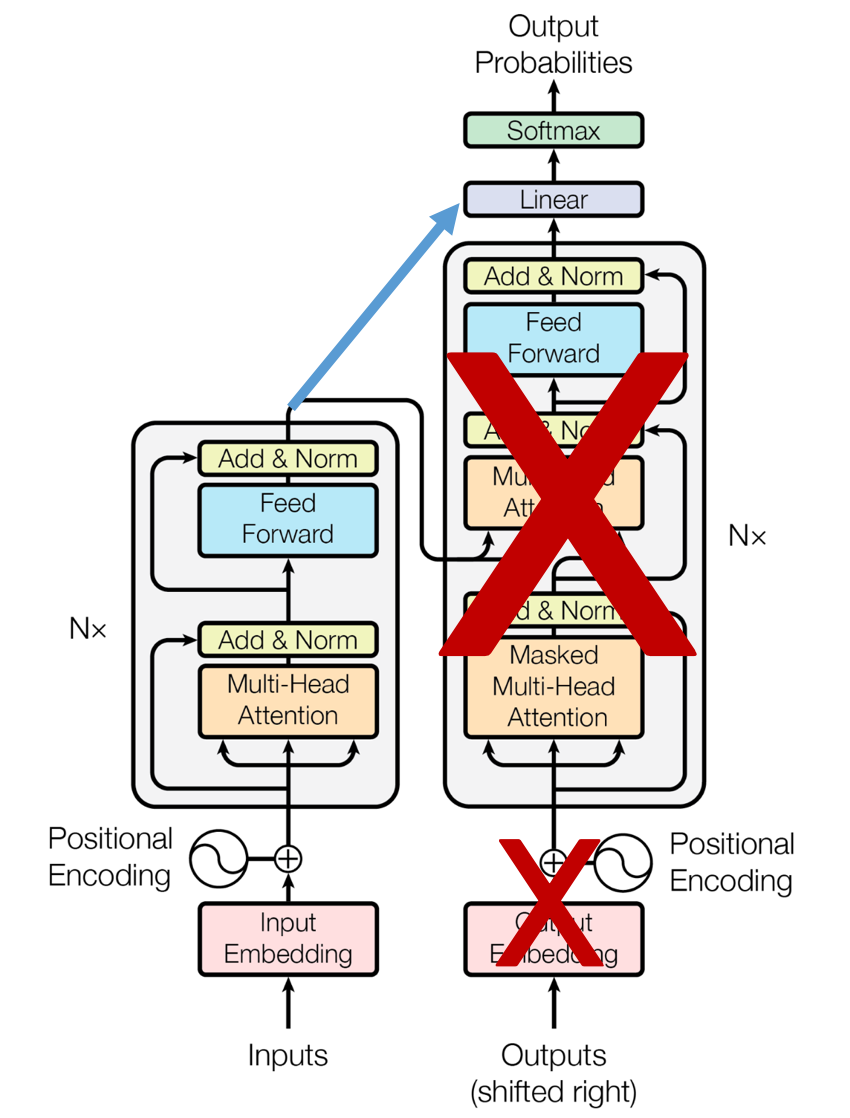
BERT에서는 입력 단어의 일부를 random+통계적으로 mask해서 해당 단어가 무엇인지 예측하는 task로 학습이 진행됩니다.
BERT와 GPT에 자세히 알고싶으시면
https://ratsgo.github.io/nlpbook/docs/language_model/bert_gpt/
BERT & GPT
pratical tips for Natural Language Processing
ratsgo.github.io
위 사이트를 참고하시면 좋을것 같습니다. 정말 잘 설명되어있습니다.
5. 정리
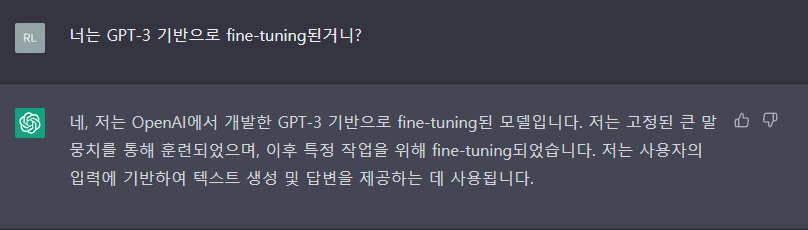
결국 ChatGPT는 GPT-3를 기반으로 Chatbot task를 위해 fine-tuning된 모델입니다. (직접 당사자에게 물어봤습니다.)
ChatGPT를 출시하고 마이크로소프트가 자사의 서비스에 모델을 추가했고, 구글은 이에대해 심각한 위기 경고를 뜻하는 code red를 사내에 발령했다고 합니다.
ChatGPT가 구글의 검색기능을 대체할수도 있을 것이라는 예측이 있었기 때문이죠. 이에 더해 Bard라는 구글만의 챗봇을 출시하기도 했습니다. 그리고 앞으로 나올 GPT-4가 또하나의 혁신을 이뤄낼지 정말 궁금합니다.
한국에서도 통신3사가 힘을 합쳐 한국형 ChatGPT를 개발하겠다고 하죠.(과연.. 잘 할수 있을까..) 물론 SKTBrain에서는 한국어 BERT인 KoBERT를 만들기도 했습니다. 이렇듯 AI가 단순히 연구자들간의 연구 경쟁(선의의 경쟁..?)을 넘어서 초거대 AI를 바탕으로한 기업간의 상업적 경쟁으로 발전하면서 안그래도 빨랐던 AI기술이 정말 폭발적으로 증가할 것이라고 저는 생각합니다. 돈이 걸린 경쟁이 정말 무섭기 때문이죠.
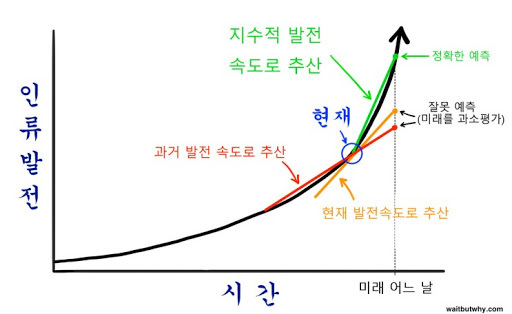
ChatGPT로 인한 경쟁이 시작되면서 '기술적 특이점'이 어쩌면 가까운 미래에 시작될수도 있겠다 라는 생각이 들었습니다.
기술적 특이점은 사람이 기술을 컨트롤할 수 있는 영역이 지나고 기술이 기술을 발전시키고 사람은 따라갈 수 없는 현상을 뜻합니다.
그리고 기술의 발전이 지수함수적으로 증가하기 때문에 시간이 갈수록 기술의 발전은 빨라지게 되겠죠. 여러 전문가들은 2045년정도가 되면 이러한 현상이 가능하게 된다고 생각하고 있습니다.
사실 지금도 딥러닝 모델이 깊어지고 복잡해 짐에 따라 그 안에서는 무슨일이 일어나고, 어떠한 근거로 결과가 나왔는지 잘 알지 못합니다.
이때문에 딥러닝 모델을 black box모델 이라고 하죠. 인간은 딥러닝 모델이 어떤 근거로, 어떻게 결과를 내뱉는지 알기 위해 XAI라는 분야를 연구중입니다. 어쩌면 이 또한 기술은 있지만 기술의 모든것은 파악하지 못하는 '기술적 특이점'의 일부일수도 있겠습니다.