
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
- Selection Sort
- Proof Selection Sort
- Binary Search Proof
- Discrete Wavelet Transform
- 선택정렬 증명
- 이진탐색 증명
- GPT-3
- binary search
- haar matrix
- ChatGPT 설명
- BERT
- chatGPT
- 선택정렬
- 이진탐색
- Today
- Total
Just Do IT
[논문리뷰] Generative Adversarial Networks 생성적 적대 신경망(GAN) - 2 본문
들어가며
상당수의 부분을 Time Travler님의 https://89douner.tistory.com/329 글에서 참고했습니다. 논문에 대해 굉장히 깊은 수준으로 다루십니다.
5-1. GAN (Part1. GAN architecture)
안녕하세요. 이번 글에서는 최초의 GAN 논문인 "Generative Adversarial Nets"을 리뷰하려고 합니다. 우선, GAN이라는 모델이 설명할 내용이 많다고 판단하여 파트를 두 개로 나누었습니다. Part1에서는 GAN a
89douner.tistory.com
Intractable Problem

전에 논문 리뷰를 진행할 때 difficulty of approximating many intractable probabilistic computations를 상호작용하는 확률 계산정도로 해석했었습니다. 하지만 intractable computation이라는 것은 컴퓨터로 할 수 없는 계산 이라고 해석하는 것이 맞습니다. 즉, 컴퓨터로 계산할 수 없는 확률을 보통 계산 할 수 있게 근사(approximating)해서 푸는데 이마저도 어렵다는 뜻 입니다. 그렇다면 intractable의 기준은 무엇일까요? 바로 다항시간 내에 풀 수 없는 문제를 intractable이라고 하고 NP문제라고도 합니다. 반대로 tractable은 다항시간 내에 풀 수 있는 문제로 P문제라고도 하죠.
여기서 다항시간이라는 말은 알고리즘을 배웠으면 알고 있는 Big-O notation으로 설명 할 수 있습니다. 어떤 상수 k에 대하여 $ O(n^k) $ 이 n에 대한 다항시간이 되는 것입니다.
현실에서는 n의 차수가 2차 이하의 시간복잡도를 갖으면 tractable problem이라고 한다고 합니다. 반대로 현실에서 3차 이상의 시간복잡도를 갖는 알고리즘은 intractable problem로 정의한다고 합니다. 더 자세한 내용은 https://89douner.tistory.com/327 에서 볼 수 있습니다.
정리하자면 generative model은 컴퓨터로 계산할 수 없는(intractable computation) 과정을 근사하여 푸는것 조차 어려웠기 때문에 성장하지 못했다는 것입니다. 물론 intractable computation을 approximate해서 generative model을 만든게 있습니다. 바로 VAE인데 다음에 공부해서 포스팅 하겠습니다.
4.1 Global optimality of $ p_g = P_{data} $
그럼 앞의 포스팅에 이어서 4.1이후를 리뷰하겠습니다. 4.1에서는 결국 Generator의 분포가 real image와 같아지는 전역 최적해를 갖는다고 했습니다. 상식적으로 생각하면 GAN모델의 generator는 real image와 분포가 같아지는 지점에서 학습이 종료되어야 합니다.

먼저 논문에서는 optimal한 generator G가 주어졌을 때 optimal discriminator D는
$$ D^*_G(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)} $$
로 나타낼 수 있다고 주장합니다.
여기에 대한 증명은 사진을 통해 설명하겠습니다. 출처는 1시간만에 GAN완전 정복하기라는 동영상으로 최윤제님이 발표하신 영상입니다.

1. G는 이미 주어졌기 때문에 식에서 지울 수 있고 D의 식으로 고칠 수 있다.

2. 두번째 식에서 noise 분포 pz에서 z를 샘플링한 것을 generator의 분포 pg에서 x를 샘플링한 것으로 바꾸면 위처럼 식을 바꿀 수 있다.

3. 위의 식을 기댓값식으로 바꾸면 다음과 같은 식으로 표현할 수 있다.

4. 위의 식에서 max가되는 D를 찾아야 하는데

5. integral을 제외하고 생각해도 max D(x)를 찾는 것은 바뀌지 않는다.

6. 위의 식을 치환하여 미분해서 0이되는 지점을 찾으면 결국 D(x)가 max되는 점을 찾을 수 있다.


7. 식을 쭉 풀어보면 논문에서 주장했던 식이 discriminator D의 global optimal이라는 것을 알 수 있다.
일단 여기까지 D는
$ D^*_G(x) = \frac{p_{data}(x)}{p_{data}(x) + p_g(x)} $에서 global optimal을 갖는다는 것이 증명됐습니다.
그러면 결론적으로 $ a=b , p_g = p_{data} $ 일때 global optimum을 갖고 그 값이 1/2인지 증명해야합니다.
이를위해선 먼저 KL divergence와 JS divergence를 알아야합니다.
KL(Kullback-Leibler) divergence
이부분은 공돌이의 수학정리노트라는 분의 설명을 참고하였습니다.
간단히 말해 KL divergence는 두 확률분포의 차이를 계산하는데 사용하는 함수인데 두 분포의 차이를 엔트로피를 이용해 계산합니다.
Entropy
엔트로피는 불확실성의 척도입니다.
예를들어 설명하자면 특정확률 p를 가진 메시지를 상대방에게 전달하는데 필요한 비트 수에 대한 기댓값으로
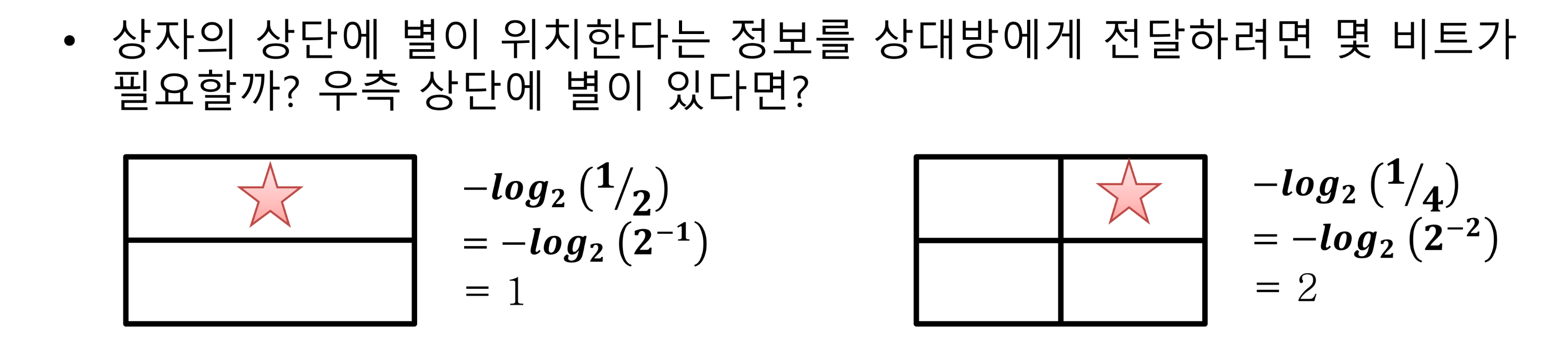
위의 예제를 참고해서 기댓값을 계산하면

위의 식처럼 나타날 수 있고 가장 애매한 확률 1/2일때 판단을 내리기 가장 힘들기 때문에 최댓값을 갖습니다.
Cross Entropy
크로스엔트로피는 엔트로피와 상당히 유사한데, 엔트로피는 정답이 나올 확률만을 대상으로 측정한 값이였다면

크로스엔트로피는 모델에서 예측한 확률값이 실제값과 비교했을때 틀릴 수 있는 정보량을 의미합니다.
먼저 binary cross entropy는 target이 $ y $, model predict 값이 $ \hat{y} $라고 했을 경우
$$ BCE = -ylog( \hat{y}) - (1-y)log(1- \hat{y}) $$
로 나타낼 수 있습니다.
target을 P(x), model predict를 Q(x)로 바꾸면

이렇게 표현할 수도 있습니다.
그리고 이를 일반화 하면 여러가지 label을 갖는 경우에 대해 크로스엔트로피

를 구할 수 있다. 크로스 엔트로피를 통해 이상적으로 생각하는 값과 실제 나온 값을 이용해 그 값이 크면 이상적인값과 실제 값의 차이가 크다고 볼 수 있습니다.
KL divergence
KL divergence는 결국 엔트로피의 상대적인 비교입니다. 크로스엔트로피로부터 수식을 유도해보면

위 식처럼 나올 수 있습니다. 즉 P의 엔트로피(크로스 엔트로피가 아님)에 추가적으로 더해진 부분을 합치면 P와 Q의 Cross entropy가 되는데 추가적으로 더해진 부분이 바로 P분포와 Q분포의 정보량 차이라는 것입니다.
그리고 그 부분을 KL divergence라고 합니다.

이 식을 더 정리하면

이렇게도 나타낼 수 있는데 P기준에서 Q와의 크로스 엔트로피와 P의 정보엔트로피의 차이로 볼 수 있습니다.
Kl divergence는 두가지 특징이 있는데

항상 0이상이라는 것과 대칭적이지 않다는 것입니다. 증명은 조금 길기때문에 직관적으로 설명하면
$ H_P(Q) - H(P) $에서 $ H_P(Q) $는 Q가 P일때 최솟값을 가진다는 사실을 생각하면 쉽습니다. 따라서 가장 작은 값은 0일 수 밖에 없습니다.
그리고 $ H_P(Q) - H(P) \neq H_Q(P) - H(Q) $ 이기 때문에 두번째 식도 만족하는 것을 알수 있습니다.
두번째 식 때문에 결국 KL divergence는 거리를 나타내는 개념으로 사용할 수 없다는 문제가 있습니다.
KLD는 두 분포의 '차이'이지 두 분포의 '거리'가 될 수 없다는 것입니다.
자세한 내용은 https://hyunw.kim/blog/2017/10/27/KL_divergence.html 를 참고하시면 될 것같습니다.
JS(Jensen-Shannon) divergence
JSD는 KLD가 거리로 나타낼 수 없다는 문제를 해결하기 위해 나왔습니다.

JSD는 단순히 KLD를 두개 구한후 평균내는 방식입니다.
길고 길게 돌아서 이러한 배경지식을 바탕으로 $ a=b , p_g = p_{data} $ 일때 global optimum을 갖고 그 값이 1/2인지 증명하겠습니다.
Theorem 1.

위 식을 밑의 식에 대입. G의 최소값은 $ D^*_G(x) $가 global optimal을 가질때 이다.

위 식을 논문에서는


이렇게 정리하고 있습니다. JSD는 항상 양수이기 때문에 C(G)는 -log(4)일때 global minimum을 갖고 $ P_{data} = P_g $일때 global optimum을 갖는다고 할 수 있습니다.
4.2 Convergence of Algorithm 1
4.2에서는 결국 이 모델을 만드는 이유인 G가 real image 분포로 수렴할 수 있는가에 대한 증명을 하고 있습니다. 즉, $ p_g $가 $ p_{data} $로 수렴할수 있는가? $ p_g $의 loss함수가 convergence할 수 있는지 따져야 하는 것입니다. 이를 위해서는 D를 고정시켰을 때의 loss 함수가 convex function인지를 확인해야합니다. 이에 관해서는 Time Travler님의 정리를 이용하겠습니다.

여기서 어떤 함수를 미분했을 때 상수 값을 갖으면 그 함수는 convex function이다 라는 특징을 이용하였습니다.
해당논문은 아래와 같이 정리했습니다.


여기서 리뷰를 마치겠습니다. 나머지 advantages and disadvantages와 experiment 부분은
https://89douner.tistory.com/331 를 참고하면 좋을 것같습니다.



